
A tese Apologia da história nas temporalidades digitais: redes intelectuais, americanismos e disciplina endereça-se às leitoras e leitores interessados na escrita da história, particularmente sobre a constituição da disciplina. Objetiva-se uma metarreflexão sobre a escrita da história que aborda a pesquisa a partir de linguagens computacionais, utilizando como experimento redes intelectuais que se dedicaram à escrita da história da América. Em outras palavras, as tensões que criaram a disciplina de história da América serão investigadas com o olhar de uma determinada história digital. Nas primeiras décadas do século XX institucionalizaram-se características importantes para a disciplina da história, principalmente no que diz respeito ao modelo pesquisador-professor. O refinamento das produções intelectuais organizadas a partir das constantes reformas do Estado moderno guarda imbricada relação com os dispositivos que mediam as relações de poder e sua diversificação, atualizando e criando redes que encontraram nas universidades e instituições de pesquisa, através da produção de diagnósticos, seu principal lugar de consolidação. A passagem das redes intelectuais para redes americanistas formadas por historiadores indica a especialização das disciplinas que ainda compõem os currículos e percursos formativos das universidades e periódicos.
A conexão com o tempo presente não permite esconder uma outra face da pesquisa, que diz respeito às abordagens computacionais mobilizadas durante a escrita da presente tese. Noções a partir de linguagem, dados, interpretação, síntese e narrativa seriam próprias das demandas de uma história digital ou já foram consideradas parte da hermenêutica historiadora? O que implica a computação como tecnologia mediadora nos procedimentos de interpretação e explicação? Ao olhar para o início do século XX, há um lugar privilegiado para estudar a relação entre computação e história. Não por uma descoberta anacrônica do uso da computação eletrônica para pesquisa histórica, anterior a Roberto Busa na década de 1940, mas pelos sentidos mobilizados em torno de análises qualitativas e quantitativas.
Ao empregar o termo temporalidades, assinalo que a pesquisa opera com escalas de tempo historicamente determinadas: (1) a temporalidade dos atores investigados – intelectuais que, desde as primeiras décadas do século XX, disputaram sentidos para América e instituíram a disciplina História da América; (2) a temporalidade epistemológica da própria disciplina histórica, cuja lógica de prova, relacionamentos, crítica documental e construção narrativa passou a ser tensionada pela cultura algorítmica; e (3) a temporalidade técnico-material do digital, marcada pela volatilidade do suporte e pela necessidade de reconfigurar permanentemente bases de dados e algoritmos. A articulação dessas três camadas evidencia que cada decisão teórico-metodológica – da coleta de documentos à modelagem computacional – está imersa em ritmos distintos de produção, circulação e preservação de conhecimento. Apesar das noções de tempo serem conhecidas da prática historiadora, a história digital sugere dinâmicas específicas para relacionar as escalas temporais.
As figuras baixos foram selecionada da tese como forma de demonstrar um pouco dos sofisticados relacionamentos que envolvem a escrita da história com a história digital, situando o problema a partir da disciplina de História da América. Os problemas e explicações foram desenvolvidos no próprio texto. O visualizador dinâmicos dos dados estão disponíveis neste mesmo site, no menu superior, no botão CronoData. Esta estrutura hospedada no Microsoft Power Bi será substituída em breve, por uma plataforma de código aberto. Os metadados da pesquisa foram publicados no Repositório de Dados da Unicamp e os algorítmicos desenvolvidos foram publicados no GitHub:
Tese:
https://hdl.handle.net/20.500.12733/31877
Algoritmos:
https://github.com/alessonrota/Ferramentas-tese-de-doutorado
Metadados:
https://redu.unicamp.br/dataset.xhtml?persistentId=doi:10.25824/redu/C2ILA2
Figura 1 – Países e instituições que foram representadas nos Congressos Internacionais de História da América (1922-1937).
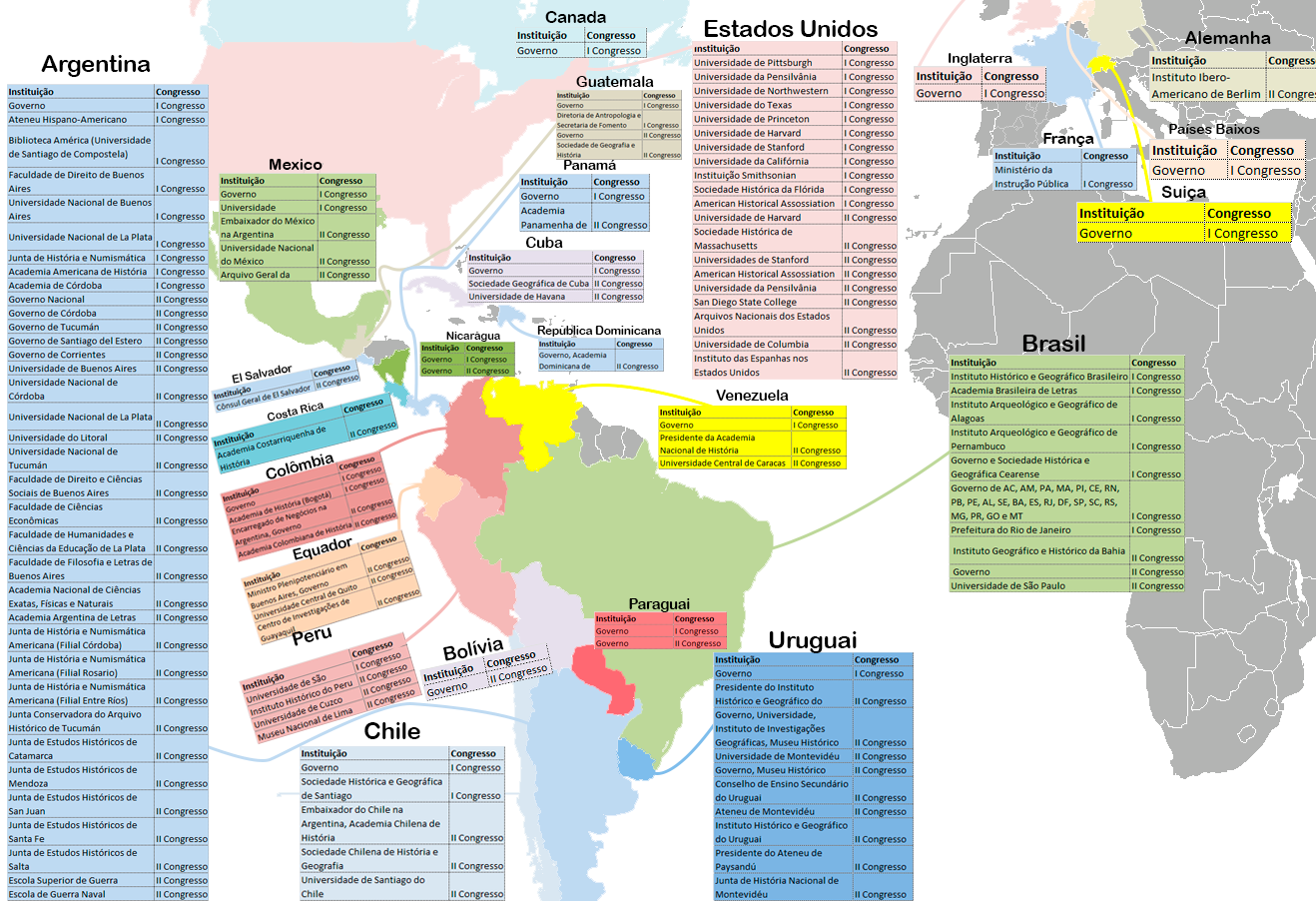 Fonte: Anais do I e II Congresso Internacional de História da América.
Fonte: Anais do I e II Congresso Internacional de História da América.
Figura 2 - Representação estática da constelação de autores delineada na pesquisa. Para uma versão interativa, acessar chd.unicamp.br.

Fonte: Metadados da pesquisa - https://doi.org/10.25824/redu/C2ILA2.
Figura 3 – Mapeamento dos acervos, período e extensão.

Fonte: Acervos digitais citados no gráfico.
Figura 8– Rede Neural Pan, Hispano, Latino e Sul de 1900 a 1921.

Fonte: Revista Americana, Boletim da Junta/Academia, Revista do IHGB, Anais do I e II Congresso Internacional de História da América.
Figura 17 - Relacionamento entre Revistas Latino-Americanas e intelectuais entre os anos de 1900 a 1940.
 Fonte: Acervo de Revistas Culturais da América Latina e Caribe do Instituto Ibero-Americano de Berlim.
Fonte: Acervo de Revistas Culturais da América Latina e Caribe do Instituto Ibero-Americano de Berlim.
Figura 18 – Repercussão de intelectuais em periódicos.
 Fonte: Academia Nacional de História da Argentina, Revista do IHGB e Hemeroteca Digital da Biblioteca Nacional.
Fonte: Academia Nacional de História da Argentina, Revista do IHGB e Hemeroteca Digital da Biblioteca Nacional.
Figura 20– Classificação de conceitos de América e suas variações.
 Fonte: Revista do IHGB, Hemeroteca Digital da Biblioteca Nacional, Anais do I e II Congresso Internacional de História da América e Boletim da Junta/Academia.
Fonte: Revista do IHGB, Hemeroteca Digital da Biblioteca Nacional, Anais do I e II Congresso Internacional de História da América e Boletim da Junta/Academia.
Figura 22– Citação de intelectuais clássicos no I e II Congresso Internacional de História da América.

Fonte: Anais do I e II Congresso Internacional de História da América.
Figura 26 - Bibliometria entre intelectuais da Argentina e do Brasil a partir de seus periódicos.
 Fonte: Revista do IHGB e Boletim da Junta/Academia Nacional de História da Argentina.
Fonte: Revista do IHGB e Boletim da Junta/Academia Nacional de História da Argentina.
Figura 27 - Representação dos intelectuais em redes. A expressara da aresta representa a quantidade de conexões. Arestas laranjas são de intelectuais que interagiram entre Brasil e Argentina, as verdes apenas Brasil e as Roxas apenas Argentina.
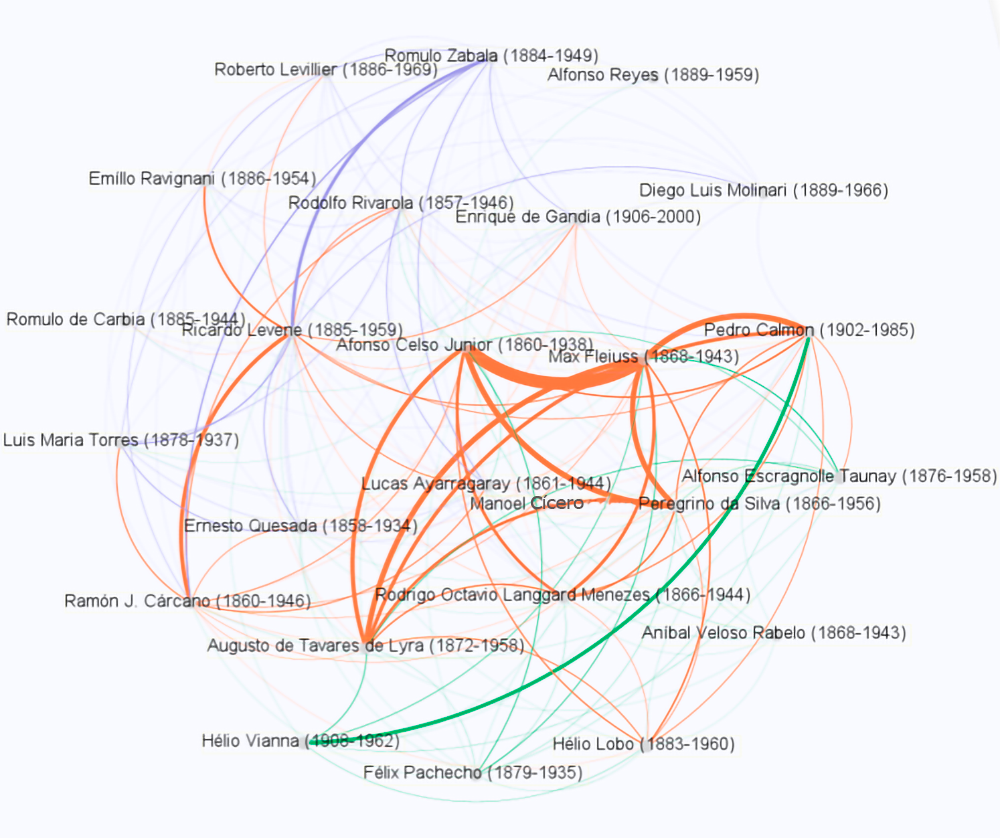 Fonte: Revista do IHGB e Boletim da Junta/Academia Nacional de História da Argentina.
Fonte: Revista do IHGB e Boletim da Junta/Academia Nacional de História da Argentina.